Groq's LPU Inference Engine-ը, որը նվիրված է Լեզուների մշակման միավորին, նոր ռեկորդ է սահմանել խոշոր լեզուների մոդելների մշակման արդյունավետության մեջ:
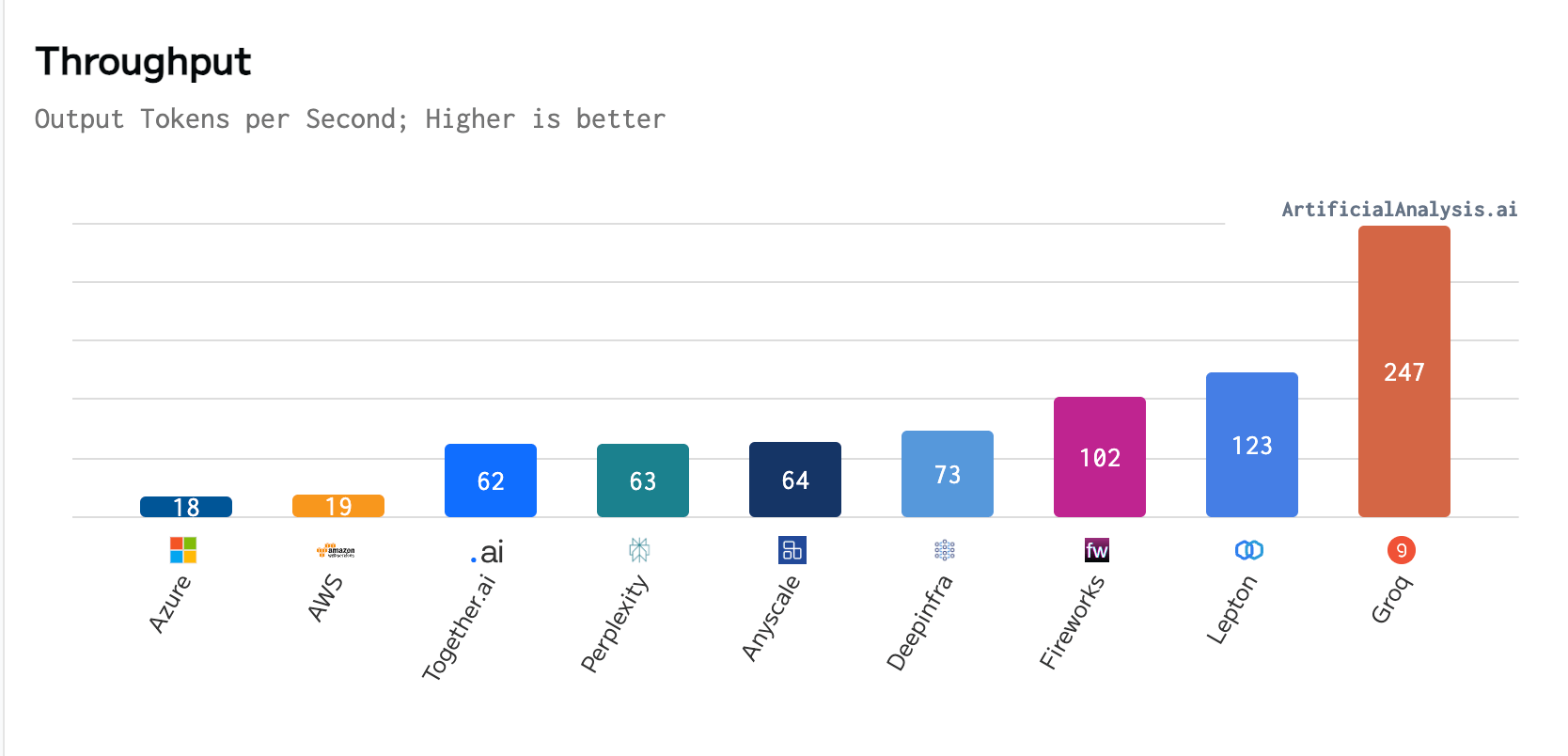
Վերջերս ArtificialAnalysis.ai-ի կողմից անցկացված հենանիշում Groq-ը գերազանցեց ութ այլ մասնակիցների՝ կատարողականի մի քանի հիմնական ցուցանիշներով, ներառյալ ուշացումն ընդդեմ թողունակության և ընդհանուր արձագանքման ժամանակի: Groq-ի կայքում նշվում է, որ LPU-ի բացառիկ կատարումը, մասնավորապես Meta AI-ի Llama 2-70b մոդելի դեպքում, նշանակում էր, որ «առանցքները պետք է երկարացվեին Groq-ի գծապատկերի վրա ուշացումն ընդդեմ թողունակության գծապատկերում»:
Ըստ ArtificialAnalysis.ai-ի, Groq LPU-ն հասել է վայրկյանում 241 նշանի թողունակության՝ զգալիորեն գերազանցելով հոստինգի այլ մատակարարների հնարավորությունները: Կատարման այս մակարդակը կրկնակի գերազանցում է մրցակցային լուծումների արագությունը և պոտենցիալ նոր հնարավորություններ է բացում տարբեր տիրույթներում մեծ լեզուների մոդելների համար: Groq-ի ներքին հենանիշերն ավելի ընդգծեցին այս ձեռքբերումը՝ հավակնելով վայրկյանում հասնել 300 նշանի, արագություն, որին ժառանգական լուծումներն ու գործող մատակարարները դեռ պետք է մոտենան:
Այս նորամուծության հիմքում ընկած է GroqCard™ արագացուցիչը, որի գինը $19,948 է և մատչելի է սպառողների համար: Տեխնիկապես, այն պարծենում է մինչև 750 TOPs (INT8) և 188 TFLOPs (FP16 @900 MHz) կատարողականությամբ, 230 ՄԲ SRAM մեկ չիպի հետ մեկտեղ և մինչև 80 TB/վ հիշողության թողունակություն՝ գերազանցելով ավանդական պրոցեսորի և GPU-ի կարգավորումները, մասնավորապես: LLM առաջադրանքներում: Այս կատարողական թռիչքը վերագրվում է LPU-ի՝ մեկ բառի հաշվարկման ժամանակը զգալիորեն նվազեցնելու և արտաքին հիշողության խցանումները մեղմելու ունակության հետ՝ դրանով իսկ հնարավորություն տալով տեքստի հաջորդականության ավելի արագ ստեղծմանը:

Համեմատելով Groq LPU քարտը NVIDIA-ի առաջատար A100 GPU-ի հետ՝ նույն արժեքով, Groq քարտը գերազանցում է այնպիսի առաջադրանքներում, որտեղ մեծ ծավալի պարզ տվյալների մշակման արագությունն ու արդյունավետությունը կարևոր են, նույնիսկ երբ A8-ն օգտագործում է առաջադեմ տեխնիկա՝ իր աշխատանքը բարձրացնելու համար: Այնուամենայնիվ, տվյալների մշակման ավելի բարդ առաջադրանքներով (FP100), որոնք պահանջում են ավելի մեծ ճշգրտություն, Groq LPU-ն չի հասնում A16-ի կատարողականի մակարդակներին:
Ըստ էության, երկու բաղադրիչներն էլ գերազանցում են AI և ML հաշվարկների տարբեր ասպեկտներում, ընդ որում, Groq LPU քարտը բացառիկ մրցունակ է LLMS արագությամբ գործարկելու գործում, մինչդեռ A100-ը տանում է այլուր: Groq-ը LPU-ն տեղադրում է որպես LLM-ների գործարկման գործիք, այլ ոչ թե հումքային հաշվարկման կամ ճշգրտման մոդելների:
Groq-ի Mixtral 8x7b մոդելի հարցումն իր կայքում հանգեցրեց հետևյալ պատասխանին, որը մշակվեց վայրկյանում 420 նշանով.
«Groq-ը հզոր գործիք է մեքենայական ուսուցման մոդելներ գործարկելու համար, հատկապես արտադրական միջավայրերում: Թեև այն չի կարող լավագույն ընտրությունը լինել մոդելի թյունինգի կամ ուսուցման համար, այն գերազանցում է նախապես պատրաստված մոդելները բարձր արդյունավետությամբ և ցածր ուշացումով:
Հիշողության թողունակության ուղղակի համեմատությունն ավելի քիչ պարզ է, քանի որ Groq LPU-ն կենտրոնացած է հիշողության թողունակության վրա, ինչը զգալիորեն օգուտ է բերում AI-ի աշխատանքային ծանրաբեռնվածությանը` նվազեցնելով ուշացումը և ավելացնելով տվյալների փոխանցման արագությունը չիպի ներսում:
Համակարգչային բաղադրիչների էվոլյուցիան AI-ի և մեքենայական ուսուցման համար
Groq-ի կողմից լեզվի մշակման միավորի ներդրումը կարող է կարևոր իրադարձություն լինել հաշվողական սարքավորումների էվոլյուցիայի մեջ: Ավանդական ԱՀ բաղադրիչները՝ CPU, GPU, HDD և RAM, մնացել են համեմատաբար անփոփոխ իրենց հիմնական ձևով GPU-ների ներդրումից ի վեր՝ ինտեգրված գրաֆիկայից տարբերվող: LPU-ն ներկայացնում է մասնագիտացված մոտեցում, որը կենտրոնացած է LLM-ների մշակման հնարավորությունների օպտիմալացման վրա, ինչը կարող է գնալով ավելի շահավետ դառնալ տեղական սարքերում գործարկելու համար: Թեև ChatGPT-ի և Gemini-ի նման ծառայություններն աշխատում են ամպային API ծառայությունների միջոցով, գաղտնիության, արդյունավետության և անվտանգության ապահովման համար LLM մշակման առավելություններն անհամար են:
GPU-ները, որոնք ի սկզբանե նախագծված էին բեռնաթափելու և արագացնելու 3D գրաֆիկայի մատուցումը, դարձել են զուգահեռ առաջադրանքների մշակման կարևոր բաղադրիչ՝ դրանք դարձնելով անփոխարինելի խաղերի և գիտական հաշվարկների մեջ: Ժամանակի ընթացքում GPU-ի դերն ընդլայնվեց AI-ի և մեքենայական ուսուցման մեջ՝ միաժամանակյա գործողություններ կատարելու ունակության շնորհիվ: Չնայած այս առաջընթացին, այս բաղադրիչների հիմնարար ճարտարապետությունը հիմնականում մնաց նույնը՝ կենտրոնանալով ընդհանուր նշանակության հաշվողական առաջադրանքների և գրաֆիկայի ներկայացման վրա:
Groq's LPU Inference Engine-ի գալուստը ներկայացնում է պարադիգմային փոփոխություն, որը հատուկ նախագծված է LLM-ների կողմից ներկայացված եզակի մարտահրավերները լուծելու համար: Ի տարբերություն պրոցեսորների և պրոցեսորների, որոնք նախատեսված են կիրառությունների լայն շրջանակի համար, LPU-ն հարմարեցված է լեզվի մշակման առաջադրանքների հաշվողականորեն ինտենսիվ և հաջորդական բնույթի համար: Այս կենտրոնացումը թույլ է տալիս LPU-ին գերազանցել ավանդական հաշվողական սարքավորումների սահմանափակումները, երբ զբաղվում է AI լեզվի հավելվածների հատուկ պահանջներով:
LPU-ի հիմնական տարբերակիչներից մեկը նրա գերազանց հաշվարկային խտությունն է և հիշողության թողունակությունը: LPU-ի դիզայնը թույլ է տալիս նրան շատ ավելի արագ մշակել տեքստային հաջորդականությունները՝ հիմնականում կրճատելով մեկ բառի հաշվարկման ժամանակը և վերացնելով արտաքին հիշողության խցանումները: Սա կարևոր առավելություն է LLM հավելվածների համար, որտեղ տեքստային հաջորդականությունների արագ գեներացումը առաջնային է:
Ի տարբերություն ավանդական կարգավորումների, որտեղ CPU-ները և GPU-ները հիշողության համար կախված են արտաքին RAM-ից, on-die հիշողությունը ինտեգրված է անմիջապես չիպի մեջ՝ առաջարկելով զգալիորեն կրճատված ուշացում և ավելի մեծ թողունակություն տվյալների փոխանցման համար: Այս ճարտարապետությունը թույլ է տալիս արագ մուտք գործել տվյալներ, որոնք կարևոր են AI աշխատանքային ծանրաբեռնվածության մշակման արդյունավետության համար՝ վերացնելով պրոցեսորի և առանձին հիշողության մոդուլների միջև տվյալների ժամանակատար ուղևորությունները: Groq LPU-ի տպավորիչ on-die հիշողության թողունակությունը մինչև 80 TB/վ ցույց է տալիս նրա կարողությունը՝ ավելի արդյունավետ կերպով կարգավորելու մեծ լեզվական մոդելների տվյալների հսկայական պահանջները, քան GPU-ները, որոնք կարող են պարծենալ բարձր անջատված հիշողության թողունակությամբ, բայց չեն կարող համապատասխանել արագությանը և արդյունավետությանը: ապահովված է «մահվան» մոտեցմամբ:
LLM-ների համար նախատեսված պրոցեսորի ստեղծումը լուծում է արհեստական ինտելեկտի հետազոտության և զարգացման համայնքի աճող կարիքը՝ ավելի մասնագիտացված ապարատային լուծումների համար: Այս քայլը կարող է պոտենցիալ կատալիզացնել նորարարության նոր ալիքը AI ապարատային ոլորտում՝ հանգեցնելով ավելի մասնագիտացված մշակման միավորների՝ հարմարեցված AI-ի և մեքենայական ուսուցման աշխատանքային ծանրաբեռնվածության տարբեր ասպեկտներին:
Քանի որ հաշվարկները շարունակում են զարգանալ, LPU-ի ներդրումը ավանդական բաղադրիչների հետ միասին, ինչպիսիք են CPU-ները և GPU-ները, ազդարարում է ապարատային զարգացման նոր փուլ, որը գնալով ավելի մասնագիտացված և օպտիմիզացված է զարգացած AI հավելվածների հատուկ պահանջների համար:
Աղբյուր՝ https://cryptoslate.com/groq-20000-lpu-card-breaks-ai-performance-records-to-rival-gpu-led-industry/